Find SQL bugs in tests, not in production
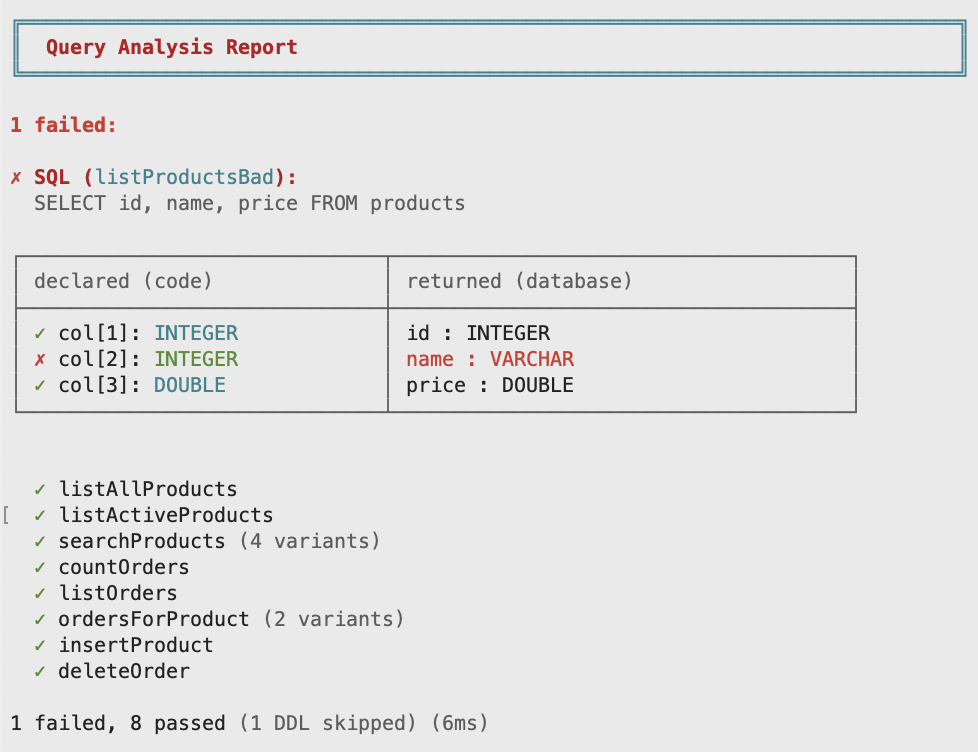
Query Analysis verifies your SQL against the actual database schema. Wrong column type? Missing .opt() on a nullable column? Parameter count mismatch? Catch it in tests, not in production.
- Kotlin
- Java
- Scala
// name is VARCHAR in the database, but declared as Int here
data class Product(val id: Int, val name: Int, val price: Double)
val listProductsBad: OperationRead.Query<List<Product>> =
Fragment.of("SELECT id, name, price FROM products")
.query(productCodec.all())
fun check() {
val checker: QueryChecker = QueryChecker.create(transactor)
checker.check(listProductsBad)
}
// name is VARCHAR in the database, but declared as INTEGER here
record Product(Integer id, Integer name, Double price) {}
OperationRead.Query<List<Product>> listProductsBad =
Fragment.of("SELECT id, name, price FROM products")
.query(productCodec.all());
void check() {
QueryChecker checker = QueryChecker.create(transactor);
checker.check(listProductsBad);
}
// name is VARCHAR in the database, but declared as Int here
case class Product(id: Int, name: Int, price: Double)
val listProductsBad: OperationRead.Query[List[Product]] =
Fragment.of("SELECT id, name, price FROM products")
.query(productCodec.all())
def check(): Unit =
val checker: QueryChecker = QueryChecker.create(transactor)
checker.check(listProductsBad)
The depth of analysis depends on what each database's JDBC driver reports. See database-specific behavior.
What existing libraries still get wrong
ORMs and query builders solve the verbosity of raw JDBC. But fundamental problems remain: problems that surface in production as silent data corruption, runtime exceptions, and database lock-in.
Queries are unchecked strings
Rename a column in the schema and nothing fails until production. No library catches this at test time.
Query Analysis catches bugs in tests
Validate every query against a real database in your test suite. Schema changes break tests, not production.
Nullability is invisible
A nullable column and a non-nullable column have the same Java type. Nothing in the API tells you which columns can be null.
Nullable means Optional
.opt() changes the return type to Optional / T? / Option[T]. If the type isn\'t optional, the column is guaranteed non-null.
Type fidelity is lost
Your DuckDB STRUCT becomes a shapeless Object. Your PostgreSQL int4range becomes a string you have to parse yourself. The database has real types. Your library ignores them.
Every database type, modeled exactly
Composite types, domains, enums, arrays, intervals. All first-class, with full roundtrip fidelity.
DB-specific features are second-class
Libraries target the lowest common denominator. PostgreSQL arrays, Oracle MULTISET, MariaDB unsigned types. All require escape hatches.
Database-specific by design
Dedicated type classes for each database. PgTypes, OracleTypes, MariaDbTypes: use your database's full feature set.
From zero to query in under a minute
DuckDB runs in-memory, no database server needed. A Fragment is a typed SQL building block.
- Java
- Kotlin
- Scala
import dev.typr.foundations.*;
import dev.typr.foundations.connect.*;
public class Main {
public static void main(String[] args) {
var tx = ConnectionSource.of(DuckDbConfig.inMemory().build()).transactor();
int answer = Fragment.of("SELECT 42")
.queryExactlyOne(DuckDbTypes.integer)
.transact(tx);
System.out.println("Result: " + answer);
}
}
- Gradle
- Maven
dependencies {
implementation("dev.typr.foundations:foundations-jdbc:1.0.0-RC1")
// Add your driver
runtimeOnly("org.duckdb:duckdb_jdbc:1.1.3")
}
<dependency>
<groupId>dev.typr.foundations</groupId>
<artifactId>foundations-jdbc</artifactId>
<version>1.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.duckdb</groupId>
<artifactId>duckdb_jdbc</artifactId>
<version>1.1.3</version>
</dependency>
import dev.typr.foundationskt.*
import dev.typr.foundationskt.connect.*
fun main() {
val tx = ConnectionSource.of(DuckDbConfig.inMemory().build()).transactor()
val answer: Int = sql { "SELECT 42" }
.queryExactlyOne(DuckDbTypes.integer)
.transact(tx)
println("Result: $answer")
}
- Gradle
- Maven
dependencies {
implementation("dev.typr.foundations:foundations-jdbc-kotlin:1.0.0-RC1")
// Add your driver
runtimeOnly("org.duckdb:duckdb_jdbc:1.1.3")
}
<dependency>
<groupId>dev.typr.foundations</groupId>
<artifactId>foundations-jdbc-kotlin</artifactId>
<version>1.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.duckdb</groupId>
<artifactId>duckdb_jdbc</artifactId>
<version>1.1.3</version>
</dependency>
import dev.typr.foundationssc.*
import dev.typr.foundationssc.Fragment.sql
import dev.typr.foundationssc.connect.*
@main def run(): Unit =
val tx = ConnectionSource.of(DuckDbConfig.inMemory().build()).transactor()
val answer: Int = sql"SELECT 42"
.queryExactlyOne(DuckDbTypes.integer)
.transact(tx)
println(s"Result: $$answer")
- Gradle
- Maven
- sbt
dependencies {
implementation("dev.typr.foundations:foundations-jdbc-scala_3:1.0.0-RC1")
// Add your driver
runtimeOnly("org.duckdb:duckdb_jdbc:1.1.3")
}
<dependency>
<groupId>dev.typr.foundations</groupId>
<artifactId>foundations-jdbc-scala_3</artifactId>
<version>1.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.duckdb</groupId>
<artifactId>duckdb_jdbc</artifactId>
<version>1.1.3</version>
</dependency>
libraryDependencies ++= Seq(
"dev.typr.foundations" % "foundations-jdbc-scala_3" % "1.0.0-RC1",
"org.duckdb" % "duckdb_jdbc" % "1.1.3" % Runtime
)
Prefer a working app? example-kotlin · example-spring-boot
Messages that actually help
When things go wrong, you get helpful messages that tell you exactly what happened, not a cryptic stack trace.


Functional to the foundations
A database library built on functional principles. Fragments, codecs, types, operations: each one is a value you compose. Same primitives top to bottom.
Composable, top to bottom
DbType, Fragment, RowCodec, Operation: every layer composes. Codecs join for tuples; left joins wrap the right side in Optional. Combine independent operations with combine, chain dependent ones with then. The library can tell the difference, and the optimizer will too.
Full roundtrip fidelity
Read a value from the database, write it back unchanged. Every type modeled exactly as the database defines it: composites, ranges, arrays, enums, domains.
Read or write, in the type
Readonly transactions are first-class. transactRead hands you a ConnectionRead; transact hands you a Connection. Operations declare what they need. The type system tells the library, and the next reviewer, what's allowed.
No reflection, no magic
Zero runtime reflection, zero bytecode generation, zero annotation processing. GraalVM native-image works out of the box. You can read every line of what runs.
Not an ORM
No entity manager, no session, no lazy loading, no dirty checking, no surprises. You write SQL, you get typed results. That's it.
Query Analysis
Verify SQL at test time. Parameter types, column types, nullability: all checked against the real database schema. Catch bugs before production.
Start with your schema
A real PostgreSQL table: a uuid, an enum, a tstzrange, a jsonb, two nullable columns. The RowCodec maps each to a DbType that knows exactly how to read and write its value. No getObject() guessing, no wasNull() checks.
CREATE TYPE plan_tier AS ENUM ('free', 'pro', 'team');
CREATE TABLE subscription (
id uuid PRIMARY KEY,
email text NOT NULL,
plan plan_tier NOT NULL,
active_range tstzrange NOT NULL,
metadata jsonb,
cancelled_at timestamptz
);
- Kotlin
- Java
- Scala
data class Subscription(
val id: UUID,
val email: String,
val plan: Plan,
val activeRange: Range<Instant>,
val metadata: Jsonb?,
val cancelledAt: Instant?
)
record Subscription(
UUID id,
String email,
Plan plan,
Range<Instant> activeRange,
Optional<Jsonb> metadata,
Optional<Instant> cancelledAt
) {}
case class Subscription(
id: UUID,
email: String,
plan: Plan,
activeRange: Range[Instant],
metadata: Option[Jsonb],
cancelledAt: Option[Instant]
)
- Kotlin
- Java
- Scala
val plan: PgType<Plan> = PgTypes.ofEnum<Plan>("plan_tier")
val subscriptionCodec: RowCodecNamed<Subscription> =
RowCodec.namedBuilder<Subscription>()
.field("id", PgTypes.uuid, Subscription::id)
.field("email", PgTypes.text, Subscription::email)
.field("plan", plan, Subscription::plan)
.field("active_range", PgTypes.tstzrange, Subscription::activeRange)
.field("metadata", PgTypes.jsonb.opt(), Subscription::metadata)
.field("cancelled_at", PgTypes.timestamptz.opt(), Subscription::cancelledAt)
.build(::Subscription)
static final PgType<Plan> plan = PgTypes.ofEnum("plan_tier", Plan.values());
static final RowCodecNamed<Subscription> subscriptionCodec =
RowCodec.<Subscription>namedBuilder()
.field("id", PgTypes.uuid, Subscription::id)
.field("email", PgTypes.text, Subscription::email)
.field("plan", plan, Subscription::plan)
.field("active_range", PgTypes.tstzrange, Subscription::activeRange)
.field("metadata", PgTypes.jsonb.opt(), Subscription::metadata)
.field("cancelled_at", PgTypes.timestamptz.opt(), Subscription::cancelledAt)
.build(Subscription::new);
val plan: PgType[Plan] = PgTypes.ofEnum("plan_tier", Plan.values)
val subscriptionCodec: RowCodecNamed[Subscription] = RowCodec
.namedBuilder[Subscription]()
.field("id", PgTypes.uuid)(_.id)
.field("email", PgTypes.text)(_.email)
.field("plan", plan)(_.plan)
.field("active_range", PgTypes.tstzrange)(_.activeRange)
.field("metadata", PgTypes.jsonb.opt)(_.metadata)
.field("cancelled_at", PgTypes.timestamptz.opt)(_.cancelledAt)
.build(Subscription.apply)
Building blocks, faithfully modeled
Composite types, wrapper types, and arrays: each database has its own type system, and each one is modeled faithfully.
- Composite Types
- Wrapper Types
- Arrays
The dimensions composite type becomes a record with typed fields. PgStruct handles the wire format.
CREATE TYPE dimensions AS (
width double precision,
height double precision,
depth double precision,
unit varchar(10)
);
- Kotlin
- Java
- Scala
data class Dim(
val width: Double, val height: Double,
val depth: Double, val unit: String
)
val dimCodec: RowCodecNamed<Dim> =
RowCodec.namedBuilder<Dim>()
.field("width", PgTypes.float8, Dim::width)
.field("height", PgTypes.float8, Dim::height)
.field("depth", PgTypes.float8, Dim::depth)
.field("unit", PgTypes.text, Dim::unit)
.build(::Dim)
// Named composite — reads and writes via CREATE TYPE dimensions
val pgType: PgType<Dim> = PgTypes.compositeOf("dimensions", dimCodec)
record Dim(Double width, Double height, Double depth, String unit) {}
static RowCodecNamed<Dim> dimCodec =
RowCodec.<Dim>namedBuilder()
.field("width", PgTypes.float8, Dim::width)
.field("height", PgTypes.float8, Dim::height)
.field("depth", PgTypes.float8, Dim::depth)
.field("unit", PgTypes.text, Dim::unit)
.build(Dim::new);
// Named composite — reads and writes via CREATE TYPE dimensions
static PgType<Dim> pgType = PgTypes.compositeOf("dimensions", dimCodec);
case class Dim(
width: Double,
height: Double,
depth: Double,
unit: String
)
val dimCodec: RowCodecNamed[Dim] =
RowCodec
.namedBuilder[Dim]()
.field("width", PgTypes.float8)(_.width)
.field("height", PgTypes.float8)(_.height)
.field("depth", PgTypes.float8)(_.depth)
.field("unit", PgTypes.text)(_.unit)
.build(Dim.apply)
// Named composite — reads and writes via CREATE TYPE dimensions
val pgType: PgType[Dim] = PgTypes.compositeOf("dimensions", dimCodec)
Call transform (two-way mapping) on a base type. You get a full codec that works in row codecs, arrays, and JSON.
CREATE TABLE products (
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
- Kotlin
- Java
- Scala
data class ProductId(val value: Int) {
companion object {
// MariaDB int -> wraps to your domain type
val mariaType: MariaType<ProductId> =
MariaTypes.int_.transform(::ProductId, ProductId::value)
}
}
record ProductId(Integer value) {
// MariaDB int -> wraps to your domain type
static MariaType<ProductId> mariaType =
MariaTypes.int_.transform(ProductId::new, ProductId::value);
}
case class ProductId(value: Int)
object ProductId:
// MariaDB int -> wraps to your domain type
val mariaType: MariaType[ProductId] =
MariaTypes.int_.transform(ProductId.apply, _.value)
Pass arrays directly. No createArrayOf, no type name strings, no connection reference.
CREATE TABLE posts (
id INTEGER,
tags VARCHAR[],
published BOOLEAN
);
- Kotlin
- Java
- Scala
// DuckDB LIST columns are first-class typed values
fun getTagSets(): List<List<String>> =
sql { "SELECT tags FROM posts WHERE published = true" }
.query(RowCodec.of(DuckDbTypes.varchar.list()).all())
.transact(tx)
// DuckDB LIST columns are first-class typed values
List<List<String>> getTagSets() {
return Fragment.of("SELECT tags FROM posts WHERE published = true")
.query(RowCodec.of(DuckDbTypes.varchar.list()).all())
.transactRead(tx);
}
// DuckDB LIST columns are first-class typed values
def getTagSets(): List[List[String]] =
sql"SELECT tags FROM posts WHERE published = true"
.query(RowCodec.of(DuckDbTypes.varchar.list).all())
.transact(tx)
Queries are values you compose
Build fragments, combine them, pass them to functions, return them from functions. The optionally DSL gives you optional filters as branch points, and Query Analysis verifies every resulting SQL shape, not just the one your test happens to take.
- Kotlin
- Java
- Scala
// Reusable conditional filters as Fragment extensions —
// each wraps `.optionally().append(...)` so calls read like domain verbs.
// Query Analysis still expands every branch at test time.
fun Fragment.matchingName(name: String?): Fragment =
optionally(name).append(" AND name LIKE ", SqlServerTypes.nvarchar)
fun Fragment.cheaperThan(max: BigDecimal?): Fragment =
optionally(max).append(" AND price < ", SqlServerTypes.decimal)
fun Fragment.activeOnly(active: Boolean): Fragment =
optionally(active).append(" AND active = 1")
val orders: List<OrderRow> =
Fragment.of("SELECT id, name, price FROM orders WHERE 1 = 1")
.matchingName(name)
.cheaperThan(maxPrice)
.activeOnly(onlyActive)
.query(orderRowCodec.all())
.run(conn)
// Reusable filter functions
static Fragment matchingName(Fragment f, Optional<String> name) {
return f.optionally(name).append(" AND name LIKE ", SqlServerTypes.nvarchar);
}
static Fragment cheaperThan(Fragment f, Optional<BigDecimal> max) {
return f.optionally(max).append(" AND price < ", SqlServerTypes.decimal);
}
static Fragment activeOnly(Fragment f, boolean active) {
return f.optionally(active).append(" AND active = 1");
}
// Compose with .pipe()
List<OrderRow> orders =
Fragment.of("SELECT id, name, price FROM orders WHERE 1 = 1")
.pipe(f -> matchingName(f, name))
.pipe(f -> cheaperThan(f, maxPrice))
.pipe(f -> activeOnly(f, onlyActive))
.query(orderRowCodec.all())
.run(conn);
// Reusable conditional filters as Fragment extensions —
// each wraps `.optionally().append(...)` so calls read like domain verbs.
// Query Analysis still expands every branch at test time.
extension (f: Fragment)
def matchingName(n: Option[String]): Fragment =
f.optionally(n).append(" AND name LIKE ", SqlServerTypes.nvarchar)
def cheaperThan(max: Option[BigDecimal]): Fragment =
f.optionally(max).append(" AND price < ", SqlServerTypes.decimal)
def activeOnly(active: Boolean): Fragment =
f.optionally(active).append(" AND active = 1")
def orders(using Connection): List[OrderRow] =
Fragment.of("SELECT id, name, price FROM orders WHERE 1 = 1")
.matchingName(name)
.cheaperThan(maxPrice)
.activeOnly(onlyActive)
.query(orderRowCodec.all())
.run
Transactions you can see
Use Spring's @Transactional if that's your style, or manage transactions explicitly with Transactor. Either way, you get typed builders for every database and full control over the lifecycle. Here with Oracle.
- Explicit
- Spring Integration
- Kotlin
- Java
- Scala
// Oracle - typed config, no JDBC URL to remember
val tx =
ConnectionSource.of(
OracleConfig.builder("localhost", 1521, "xe", "app", "secret")
.serviceName("XEPDB1")
.build()
).transactor()
// Everything inside runs in one transaction
fun getGreeting(): String =
sql { "SELECT 'Hello from Oracle' FROM dual" }
.query(RowCodec.of(OracleTypes.varchar2).exactlyOne())
.transact(tx)
// Oracle - typed config, no JDBC URL to remember
Transactor tx =
Transactor.create(
OracleConfig.builder("localhost", 1521, "xe", "app", "secret")
.serviceName("XEPDB1")
.build());
// Everything inside runs in one transaction
String getGreeting() {
return Fragment.of("SELECT 'Hello from Oracle' FROM dual")
.query(RowCodec.of(OracleTypes.varchar2).exactlyOne())
.transactRead(tx);
}
// Oracle - typed config, no JDBC URL to remember
val tx =
ConnectionSource
.of(
OracleConfig
.builder(
"localhost",
1521,
"xe",
"app",
"secret"
)
.serviceName("XEPDB1")
.build()
)
.transactor()
// Everything inside runs in one transaction
def getGreeting(): String =
sql"SELECT 'Hello from Oracle' FROM dual"
.query(RowCodec.of(OracleTypes.varchar2).exactlyOne())
.transact(tx)
- Kotlin
- Java
- Scala
@Service
class OrderService(private val tx: Transactor) {
@Transactional
fun getGreeting(): String =
sql { "SELECT 'Hello from Oracle' FROM dual" }
.query(RowCodec.of(OracleTypes.varchar2).exactlyOne())
.transact(tx)
}
@Service
class OrderService {
private final Transactor tx;
OrderService(Transactor tx) {
this.tx = tx;
}
@Transactional
String getGreeting() {
return Fragment.of("SELECT 'Hello from Oracle' FROM dual")
.query(RowCodec.of(OracleTypes.varchar2).exactlyOne())
.transactRead(tx);
}
}
@Service
class OrderService(tx: Transactor):
@Transactional
def getGreeting(): String =
sql"SELECT 'Hello from Oracle' FROM dual"
.query(RowCodec.of(OracleTypes.varchar2).exactlyOne())
.transact(tx)
Built-in JSON codecs
All databases can transfer data as JSON, and now you can use it uniformly. Your RowCodec doubles as a JSON codec with zero extra code. Aggregate child rows with json_agg(), JSON_ARRAYAGG, or FOR JSON and parse them with the same types.
- Kotlin
- Java
- Scala
// RowCodec → JSON column type, zero extra code
val linesType: DuckDbType<List<OrderLine>> =
DuckDbTypes.jsonArrayEncodedList(lineCodec)
fun getOrderLines(customerId: Int): List<OrderLine> =
sql { """
SELECT json_group_array(json_array(product, qty, price))
FROM order_lines
WHERE customer_id = ${DuckDbTypes.integer(customerId)}
""" }
.query(RowCodec.of(linesType).exactlyOne())
.transact(tx)
// RowCodec → JSON column type, zero extra code
DuckDbType<List<OrderLine>> linesType = DuckDbTypes.jsonArrayEncodedList(lineCodec);
List<OrderLine> getOrderLines(int customerId) {
return Fragment.of(
"""
SELECT json_group_array(\
json_array(product, qty, price))
FROM order_lines
WHERE customer_id =\
""")
.value(DuckDbTypes.integer, customerId)
.query(RowCodec.of(linesType).exactlyOne())
.transactRead(tx);
}
// RowCodec → JSON column type, zero extra code
val linesType: DuckDbType[List[OrderLine]] =
DuckDbTypes.jsonArrayEncodedList(lineCodec)
def getOrderLines(customerId: Int): List[OrderLine] =
sql"""SELECT json_group_array(
json_array(product, qty, price))
FROM order_lines
WHERE customer_id =
${DuckDbTypes.integer(customerId)}"""
.query(RowCodec.of(linesType).exactlyOne())
.transact(tx)
Call any routine like a typed function
Define a procedure or function once. The builder tracks IN and OUT types statically. Functions use SELECT so every DbType reads correctly through the normal codec path. OUT params use a CallableStatement adapter that reuses the same DbRead logic.
- Kotlin
- Java
- Scala
// Define once, call many times — input and output types are baked in
val getUser: DbProcedure.Def1_2<Int, String, String> =
DbProcedure.define("get_user_by_id")
.input(PgTypes.int4)
.out(PgTypes.text)
.out(PgTypes.text)
.build()
// call() returns an Operation — use it like any other operation
fun findUser(userId: Int): Pair<String, String> =
getUser.call(userId).transact(tx)
// Define once, call many times — input and output types are baked in
static final DbProcedure.Def1_2<Integer, String, String> getUser =
DbProcedure.define("get_user_by_id")
.input(PgTypes.int4)
.out(PgTypes.text)
.out(PgTypes.text)
.build();
// call() returns an Operation — compose it like any other query
Tuple.Tuple2<String, String> findUser(int userId) {
return getUser.call(userId).transact(tx);
}
// Define once, call many times — input and output types are baked in
val getUser: DbProcedure.Def1_2[Int, String, String] =
DbProcedure
.define("get_user_by_id")
.input(PgTypes.int4)
.out(PgTypes.text)
.out(PgTypes.text)
.build()
// call() returns an Operation — use it like any other operation
def findUser(userId: Int): (String, String) =
getUser.call(userId).transact(tx)
Seven databases, full type fidelity
The same approach works across all supported databases. Full roundtrip fidelity for every type each one supports. More databases coming soon.
How it compares
| Foundations | jOOQ | Hibernate | JDBI | JdbcTemplate | Exposed | |
|---|---|---|---|---|---|---|
| Approach | SQL + typed codecs | Type-safe DSL + codegen | ORM with entity mapping | SQL + annotations | SQL + RowMapper | Kotlin DSL |
| Languages | Java, Kotlin, Scala | Java, Kotlin, ScalajOOQ ships a KotlinGenerator (data classes) and ScalaGenerator / Scala3Generator (case classes), so Kotlin and Scala callers get generated code in their own language. Caveats: arrays still surface as Java arrays / List, Scala nullable columns are not mapped to Option[T], and Kotlin non-null types for NOT NULL columns require opt-in flags (kotlinNotNullRecordAttributes et al.) that don't apply to derived columns. Foundations ships dedicated Kotlin and Scala wrappers, native collections, T? in Kotlin, and Option[T] in Scala, idiomatic by default, no flags required. | Java, Kotlin | Java, Kotlin | Java, Kotlin | Kotlin only |
| Database portability | Database-specificType references are explicit and searchable: find all PgTypes. and replace with MariaTypes.. Then run Query Analysis to verify every query against the new database at test time. More manual than hoping an abstraction holds, but nothing slips through unchecked. | Multi-dialect DSL | HQL: dialect leaks at runtime | Raw SQL: portable until it isn't | Raw SQL: portable until it isn't | DSL: dialect-specific extensions |
| Type model | Every database type | Every database type | Java types only | Basic + custom | Basic Java types | Kotlin types + custom |
| Composites, arrays, ranges | First-class | PartialjOOQ has first-class PostgreSQL array support. PostgreSQL and Oracle composite UDTs are generated by codegen. PostgreSQL ranges are available via the jooq-postgres-extensions module (not the core DSL). Other vendor-specific types (hstore, geometric) typically require custom bindings. | PartialHibernate 6.2+ has @Struct for composites and built-in basic array mapping. Ranges still need third-party libraries (Hypersistence Utils). | Manual mapping | Raw JDBC only | PartialExposed has built-in array support. Ranges and composite types require custom ColumnType implementations. |
| ReflectionReflection affects GraalVM native-image compatibility, startup time, and debuggability. Libraries using runtime proxies or bytecode generation require additional configuration for native compilation. | None | DSL-onlyjOOQ's DSL runs without reflection, but the default record-to-POJO mapper (DefaultRecordMapper) uses reflection for constructor and setter lookup, and GraalVM native-image requires reflection configuration for jOOQ internals and generated classes. | Heavy | Moderate | None (manual mapper) | DAO layer |
| Query type checking | At test time (hand-written SQL) | DSL only (compile)jOOQ's compile-time checking applies to its DSL. Queries written as plain SQL strings (DSL.sql(...), .fetch(String), or resultQuery) are not type-checked. jOOQ's SQL parser can parse and transform SQL strings but does not validate them against the schema. Foundations validates hand-written SQL against the real database schema at test time. | Opt-in@CheckHQL (6.3+) validates HQL at compile time against the entity metamodel, not the database schema. Not enabled by default. | No | No | DSL only (compile) |
| Type-safe nullable columns | Optional<T> / T? / Option[T] | Not type-safejOOQ's Field<T> is not null-aware: nullable and non-null columns share the same type. record.getValue(field) returns plain T, possibly null at runtime regardless of the schema. Java has no Optional<T> codegen; JSR-305 @Nullable annotations can be emitted as an opt-in. The Kotlin generator can emit non-null Kotlin types for NOT NULL columns via kotlinNotNullRecordAttributes / kotlinNotNullPojoAttributes, but these are off by default and don't help with derived columns (LEFT JOIN, UNION, DEFAULT, IDENTITY). Scala generators do not map nullable columns to Option[T]. | @Column(nullable) | Manual null checks | Manual null checks | T? in Kotlin |
| Code generation | Coming soon | Mature, schema-drivenjOOQ Open Source Edition (Apache-2.0) supports PostgreSQL, MySQL/MariaDB, SQLite, H2, Derby, HSQLDB, Firebird, DuckDB, YugabyteDB, Trino, and ClickHouse. Commercial licenses (Express / Professional / Enterprise, per-developer) are required for Oracle, SQL Server, and CockroachDB (Express+); Redshift (Professional+); and DB2, Sybase, Snowflake, Teradata, Vertica, HANA, Exasol, BigQuery, and Databricks (Enterprise only). | Reverse engineeringHibernate Tools generates entity classes from database schemas. | Not supported | Not supported | Gradle pluginOfficial JetBrains plugin generates Exposed table definitions from database schemas. |
Ready to try it?
Foundations JDBC is open source, MIT-licensed, and ready to use today.
Coming soon
Generate all the RowCodecs, type definitions, and repository scaffolding you see above, directly from your database schema. Write queries in a type-safe SQL DSL that composes like the language it's embedded in.
We've been working on something that fundamentally changes what's possible with PostgreSQL on the JVM. It bypasses JDBC entirely, speaks the PostgreSQL wire protocol directly, and unlocks a class of optimizations that no connection pool or driver can offer today. The same Fragments, RowCodecs, and Operations you write today will run on it without changing a line of code.